
Machine Hee-hee 101 EP7
Decision Tree EP 4
จากบทความที่แล้วผมได้ทำการหา Gain ประเภทตัวเลข ซึ่งทำให้เราสามารถหา Gain ได้ทุกประเภทแล้วนะครับ
ในครั้งนี้เราจะเอาข้อมูลที่ได้จาก 2 บทความก่อนมาใช้นะครับ
อีกทั้งในบทความนี้เราจะจบในส่วนของ Decision Tree ในทฤษฎี (สักที)
เพื่อให้ไม่เป็นการเสียเวลา เราไปเริ่มกันเลยดีกว่า
จากการคำนวณของ 2 บทความก่อน เราสามารถหาค่าได้ทั้งหมดดังนี้
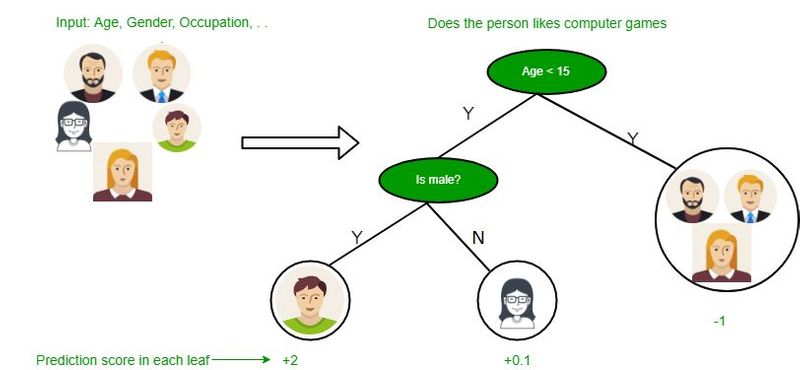
ถ้าเราใช้วิธีแบบ ID3 เราจะเอา Feature Outlook มาเป็น node
ถ้าใช้ C4.5 เราจะใช้ Humidity ซึ่งเราใช้วิธีการคำนวณแบบ C4.5
ดังนั้นเราจะเอา Feature Humidity มาใช้
เราจะสร้าง node ได้ตามนี้
โดยเราจะแตกกิ่ง ตามกฎที่เราตั้งไว้ (ถ้าเป็นประเภท ก็จะแตกตามประเภทต่างๆ ถ้าเป็นตัวเลขก็จะทำการเปรียบเทียบตามค่าเฉลี่ย)
โดยในที่นี้เราจะแตกกิ่งข้อมูลที่ < 80.3 และ >= 80.3
จากนั้นเราจะกรองข้อมูลตาม กฎ ของกิ่ง
ฝั่งซ้าย จะมีแต่ข้อมูลที่ Humidity < 80.3
ฝั่งขวา จะเป็นข้อมูลที่ Humidity >= 80.3
ข้อมูลที่ Humidity < 80.3 เกิดจากการกรองของ parent node
(อย่าลืมเอา Feature Humidity ออกด้วย)
เมื่อเราได้ข้อมูลที่ถูกกรองแล้ว เราจะใช้ข้อมูลที่ถูกกรองเหล่านี้มาหา Feature ที่สามารถแยกผลลัพธ์ได้เพื่อหา node ถัดไป
(คิดซะว่า ข้อมูลที่ถูกกรองเหล่านี้เหมือนข้อมูลอันใหม่)
จากนั้นเราจะทำการคำนวณเหมือน Step 1 – Step 3 ตามบทความที่แล้ว (การทำแบบนี้เราสามารถเรียกได้ว่ามีการทำงาน แบบ Recursive หรือเรียกว่า การทำงานด้วยตนเอง)
ในที่นี้ผมทำการหา Feature ของข้อมูล Humidity < 80.3 ก่อน
ทำให้ผมได้ค่า Gain ของแต่ละ Feature ดังนี้
ดังนั้นเราจะเลือก Feature Wind มาเป็น Child Node ของ Humidity เราสามารถสร้าง Tree ได้รูปแบบนี้
หากเราสังเกตดี ๆ ทุกๆ Weak ใน Columns จะได้คำตอบเป็น Yes
แต่เนื่องจากเราไม่รู้ว่า Feature อื่นจะมีลักษณะเดียวกันหรือไม่
ดังนั้นจึงต้องคำนวณ
ถ้าสังเกตแล้วจะพบเจอว่า Humidity ที่น้อยกว่า 80.3 และ Wind เป็น weak เราจะได้ output เหมือนกัน
นั้นหมายถึงว่าไม่มีการปะปนของข้อมูล และไม่มี Node อื่นให้ต่อลงไปจึงมีแค่ leaf node ที่มีค่าเป็น Yes เท่านั้น
จากนั้นให้ลองทำแบบนี้ไปเรื่อย ๆ จนกว่าจะกรองข้อมูลได้ครบ (ไม่มีการปะปนของข้อมูล) เราจะได้รูปตามนี้
หากเราสังเกต เราจะไม่เห็น Columns ของ Temp เลยนั้นแปลว่า Temp ไม่ได้ถูกใช้ในการ Predict ดังนั้นเราสามารถลบ Temp ไปได้ตั้งแต่แรก
แต่อย่าลืมนะครับว่า
- 1.เราไม่รู้ตั้งแต่แรกว่า Feature ไหนใช้หรือไม่ได้ใช้ ดังนั้นต้องทำทุก Feature
- 2.ในความเป็นจริงแล้วนั้น เราไม่สามารถตอบได้ว่าหากมีข้อมูลเพิ่มขึ้น Temp จะถูกใช้ในการ Predict หรือไม่ เพราะยิ่งข้อมูลเพิ่มขึ้นการสร้างต้นไม้ก็มีการเปลี่ยนแปลงเหมือนกัน
ข้อที่ควรต้องจำไว้
- 1.จำไว้ว่า Gain นั้นสามารถคำนวณได้แบบ Entropy และ Gini ซึ่งในตัวอย่างนี้จะเป็นตัวอย่างที่ใช้ Gini นั้นหมายความว่า เรายังสามารถมี Tree อีกแบบหนึ่งโดยใช้ Entropy ได้
- 2.เราสามารถใช้ ID 3 หรือ C4.5 ก็ได้ (ถ้าในข้อมูลไม่มีข้อมูลประเภทตัวเลข) แต่อย่าลืมว่า ID3 นั้นไม่มีการตัดเล็มต้นไม้ดังนั้นค่าอาจเกิด Overfitting ได้มากกว่า C4.5
- 3.หมายความว่าเราสามารถมี Tree ได้ 4 แบบเลยทีเดียว
- 4.เราไม่สามารถวัดได้ว่าแบบไหนดีที่สุด นอกจากการทดสอบ accuracy โดยการป้อน Test data เพื่อวัดความแม่นยำของตัว algorithm ที่เราเลือกมา
ถ้าให้ผมสรุปผมคิดว่า Algorithm Decision Tree เหมาะกับการใช้ข้อมูลที่จำแนกประเภท มากกว่า ข้อมูลชนิดตัวเลข
อีกทั้งแต่ละประเภทควรจะมีผลลัพธ์ที่เท่ากัน เพื่อความ Balance ของข้อมูล (ใน Course นี้เราไม่ได้พูดถึง Data analysis ดังนั้นเราจะข้ามมันไป)
สำหรับ Decision Tree ก็จะมีอยู่เท่านี้ครับ ขอบคุณทุกท่านที่อ่านจบครับ บอกตามตรงว่า ผมใช้แรงในการคำนวณเยอะมาก 2-3 ชม เลยทีเดียว
และผมคิดว่าคนที่ได้ลองทำแต่แรกจะเข้าใจว่า มันกินแรงและเวลาอย่างมาก
สำหรับคนที่ยังไม่เข้าใจ ผมจะลองแปะข้อมูลไว้ให้เพื่อให้ทุกท่านอ่านเพิ่มเติมได้นะครับ
สำหรับวันนี้สวัสดีครับ :)
อธิบายหลักการ การคัดเลือก Feature

การคัดเลือก Feature ประเภทตัวเลข
Dataset ที่เอามาใช้ในการนำเสนอ

Split infomation


ดูเพิ่มเติมในซีรีส์
โฆษณา
- ดาวน์โหลดแอปพลิเคชัน
- © 2025 Blockdit

